|
Welcome! Chenjie Cao is at Tencent Hunyuan3D, working as a researcher of computer vision. He received his Ph.D. degree from Fudan University supervised by Prof. Yanwei Fu. His research interests focus on computer vision, which includes image inpainting, image synthesis, multi-view stereo, 3D reconstruction and generation, and video generation. Email / CV / Google Scholar / GitHub |

|
|
* Researcher of Tencent Hunyuan3D, 2025.7 - present. * Researcher of DAMO Academy, Alibaba Group, 2024.1 - 2025.7. * Post doc of Computer Science and Technology, Fudan University, 2024 - present. * Ph.D of Statistics (Machine Learning track), Fudan University, 2020 - 2024. * Algorithm engineer, PingAn OneConnect, 2019 - 2020. * Master of Computer Science and Technology, East China University of Science and Technology (ECUST), 2016 - 2019. * Bachelor of Computer Science and Technology, East China University of Science and Technology (ECUST), 2012 - 2016. |
|
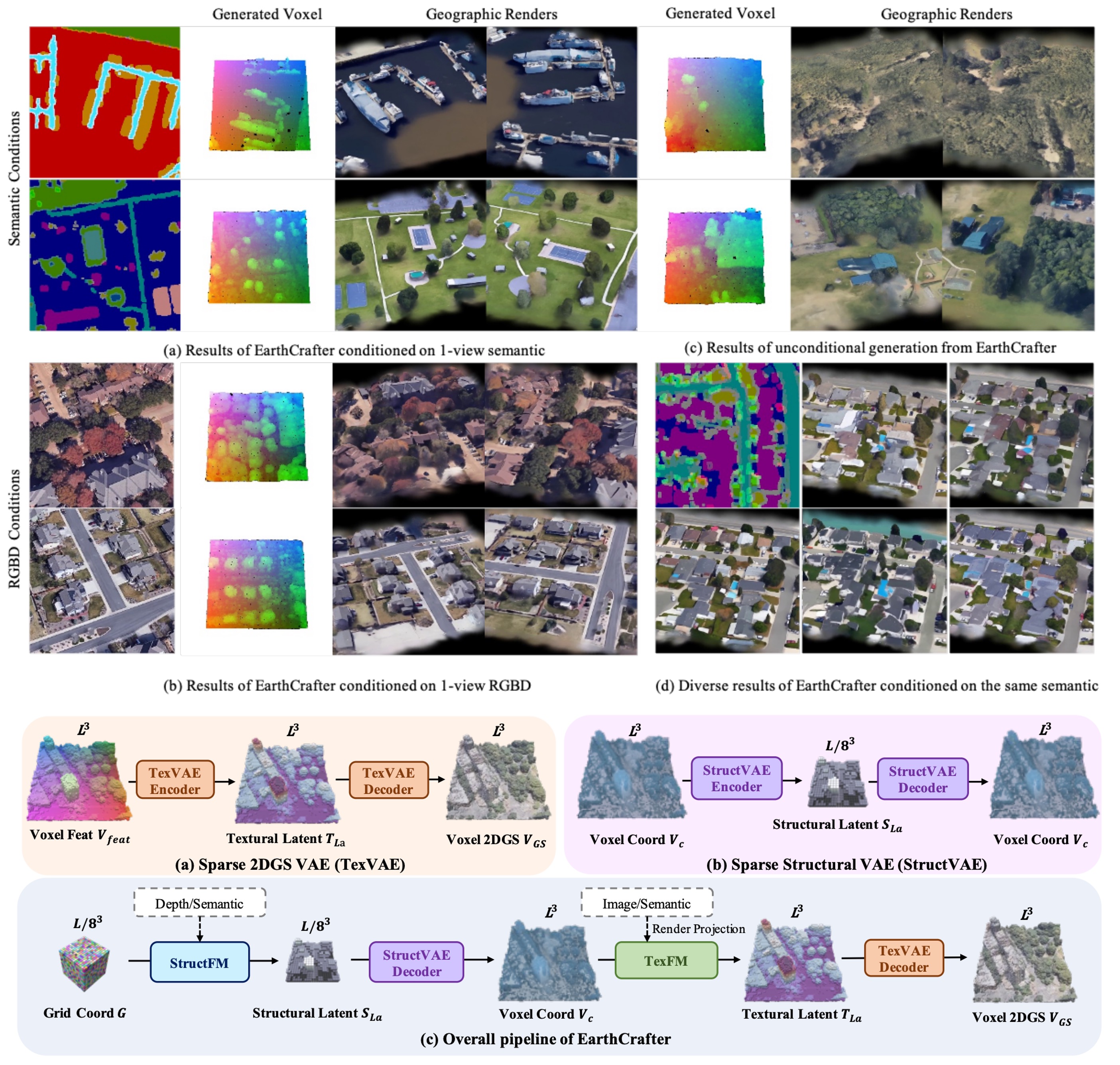
Shang Liu*, Chenjie Cao*, Chaohui Yu, Wen Qian, Jing Wang, Fan Wang AAAI 2026 (Oral) paper In this paper, we propose a geographic 3D generation framework called EarthCrafter to address extremely large-scale 3D generation. We also propose Aerial-Earth3D, the largest 3D aerial dataset to date, consisting of 50k curated scenes (each measuring 600m x 600m) captured across the U.S. mainland, comprising 45M multi-view Google Earth frames. |

|
Chenjie Cao, Jingkai Zhou, Shikai Li, Jingyun Liang, Chaohui Yu, Fan Wang, Xiangyang Xue, Yanwei Fu Siggraph Asia 2025 page / paper / code Uni3C is a unified 3D-enhanced framework for precise control of both camera and human motion in video generation. Uni3C includes two key contributions: 1) sa plug-and-play generalized camera control module, called PCDController; 2) we propose a jointly aligned 3D world guidance for the inference phase that seamlessly integrates both scenic point clouds and SMPL-X characters to unify the control signals for camera and human motion. |

|
Yisu Zhang*, Chenjie Cao*, Chaohui Yu, Jianke Zhu ICCV 2025 paper We propose LiON-LoRA, a novel framework that rethinks LoRA fusion through three core principles: linear scalability, orthogonality, and norm consistency for video control. |
|
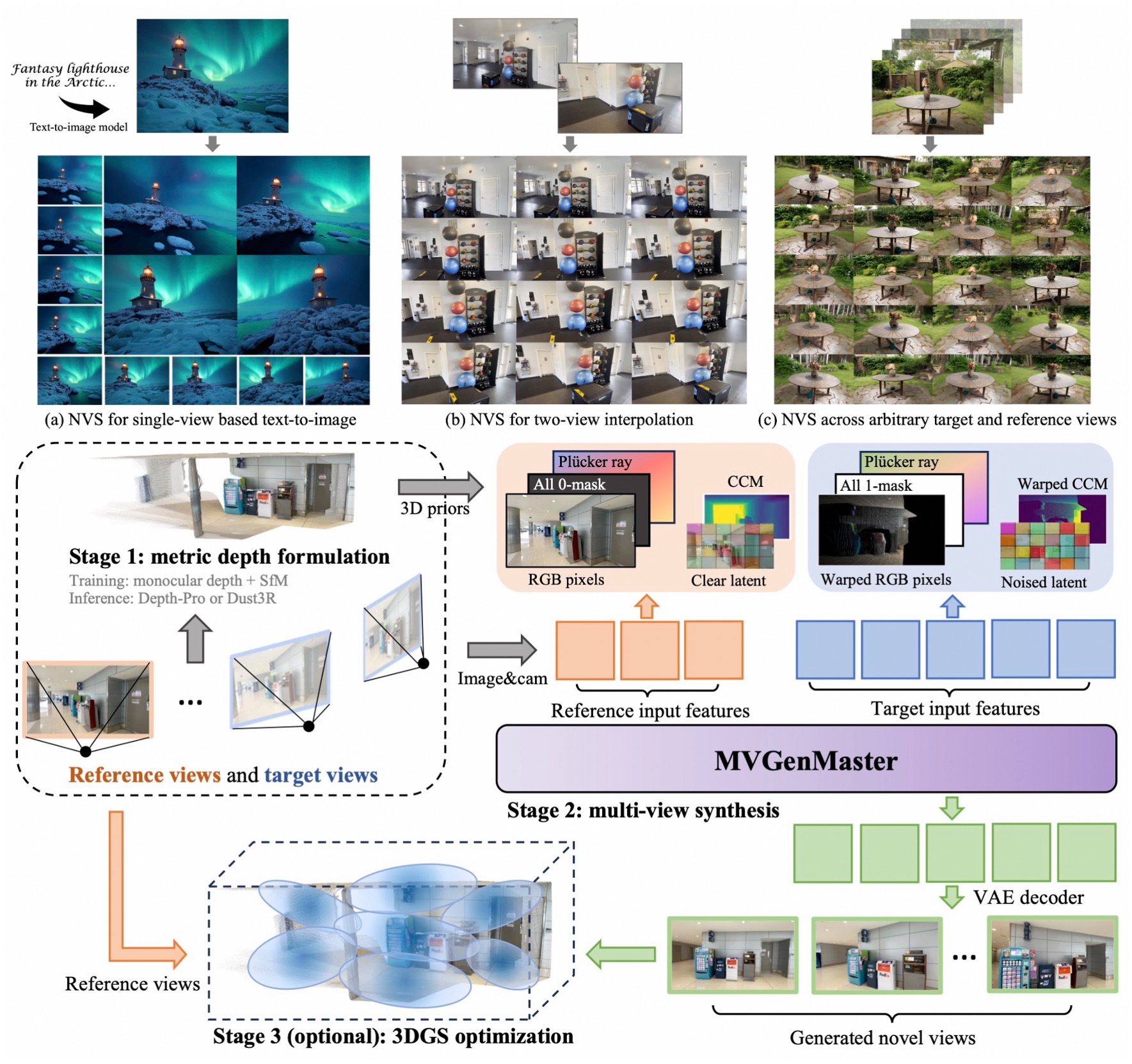
Chenjie Cao, Chaohui Yu, Shang Liu, Fan Wang, Xiangyang Xue, Yanwei Fu CVPR 2025 page / paper / code We introduce MVGenMaster, a multi-view diffusion model enhanced with 3D priors to address versatile Novel View Synthesis (NVS) tasks. MVGenMaster leverages 3D priors that are warped using metric depth and camera poses, significantly enhancing both generalization and 3D consistency in NVS. |
|
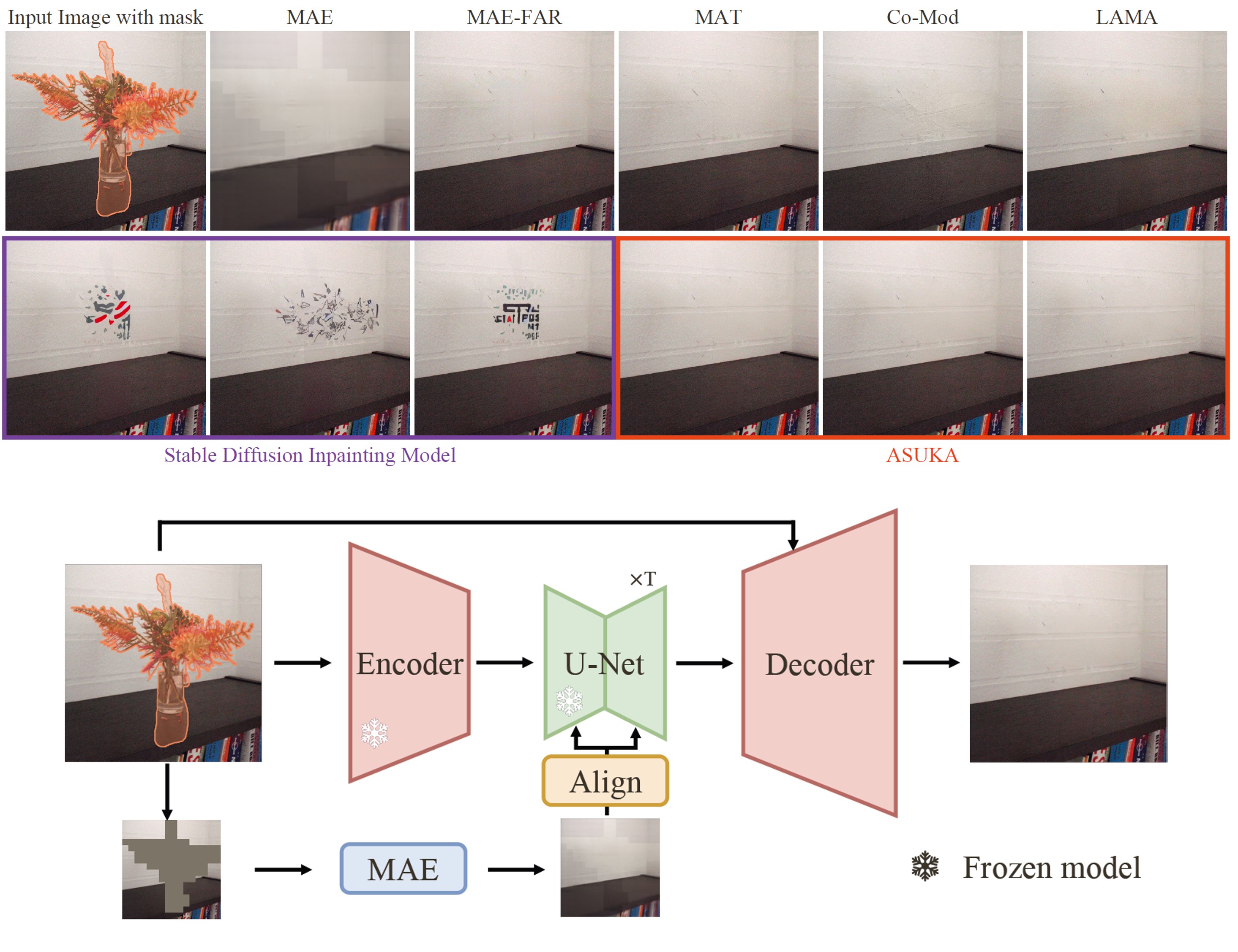
Yikai Wang*, Chenjie Cao*, Junqiu Yu*, Ke Fan, Xiangyang Xue, Yanwei Fu CVPR 2025 (Highlight) page / paper Leveraging MAE priors to stabilize the inpainting of StableDiffusion and FLUX. Moreover, we propose an effective augmentation strategy to eliminate the chromatic aberration in inpainting. |
|
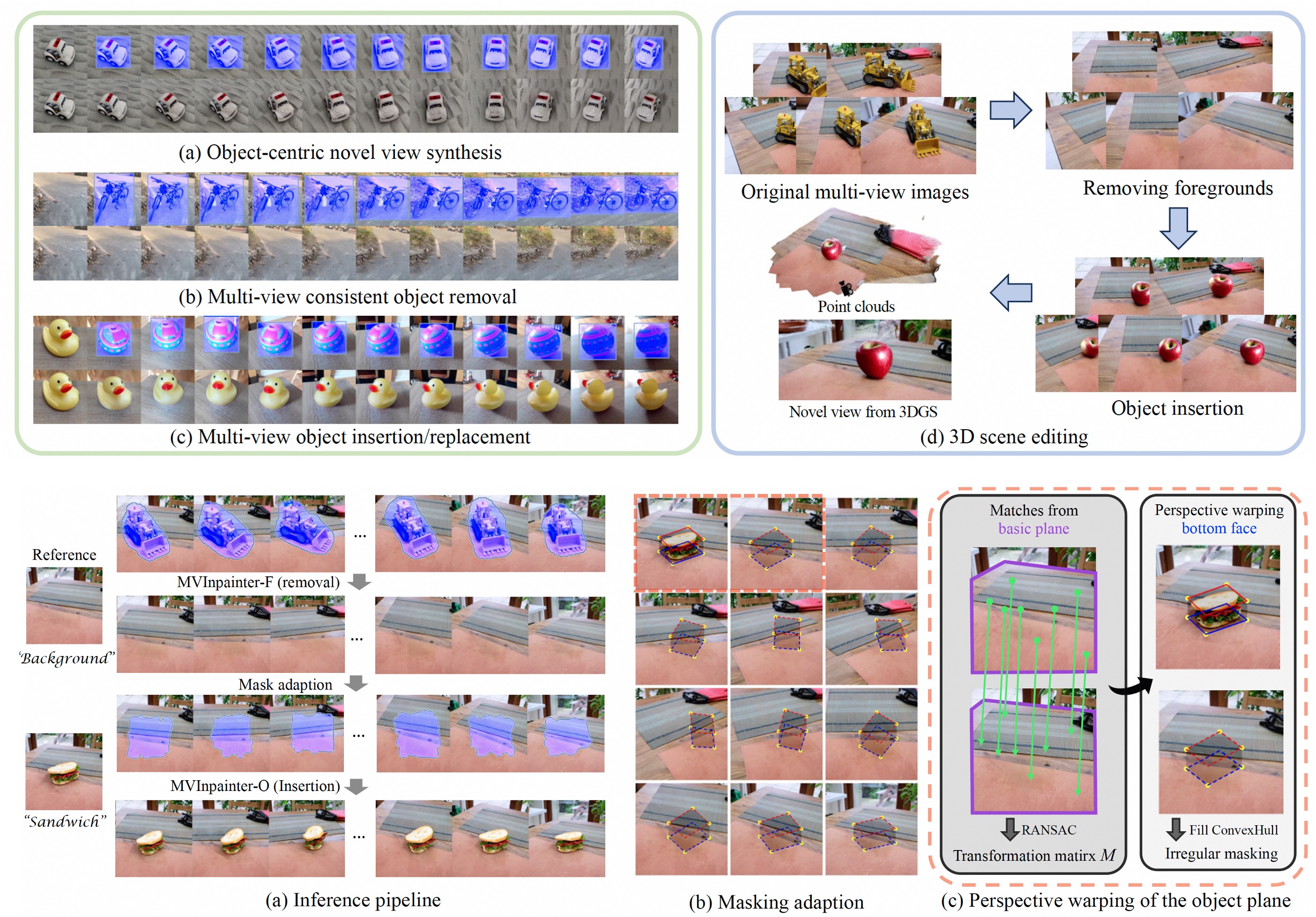
Chenjie Cao, Chaohui Yu, Yanwei Fu, Fan Wang, Xiangyang Xue NeurIPS 2024 page / paper / code In this work, we propose MVInpainter, re-formulating the 3D editing as a multi-view 2D inpainting task. Specifically, MVInpainter inpaints multi-view images with the reference guidance rather than intractably generating an entirely novel view from scratch. |
|
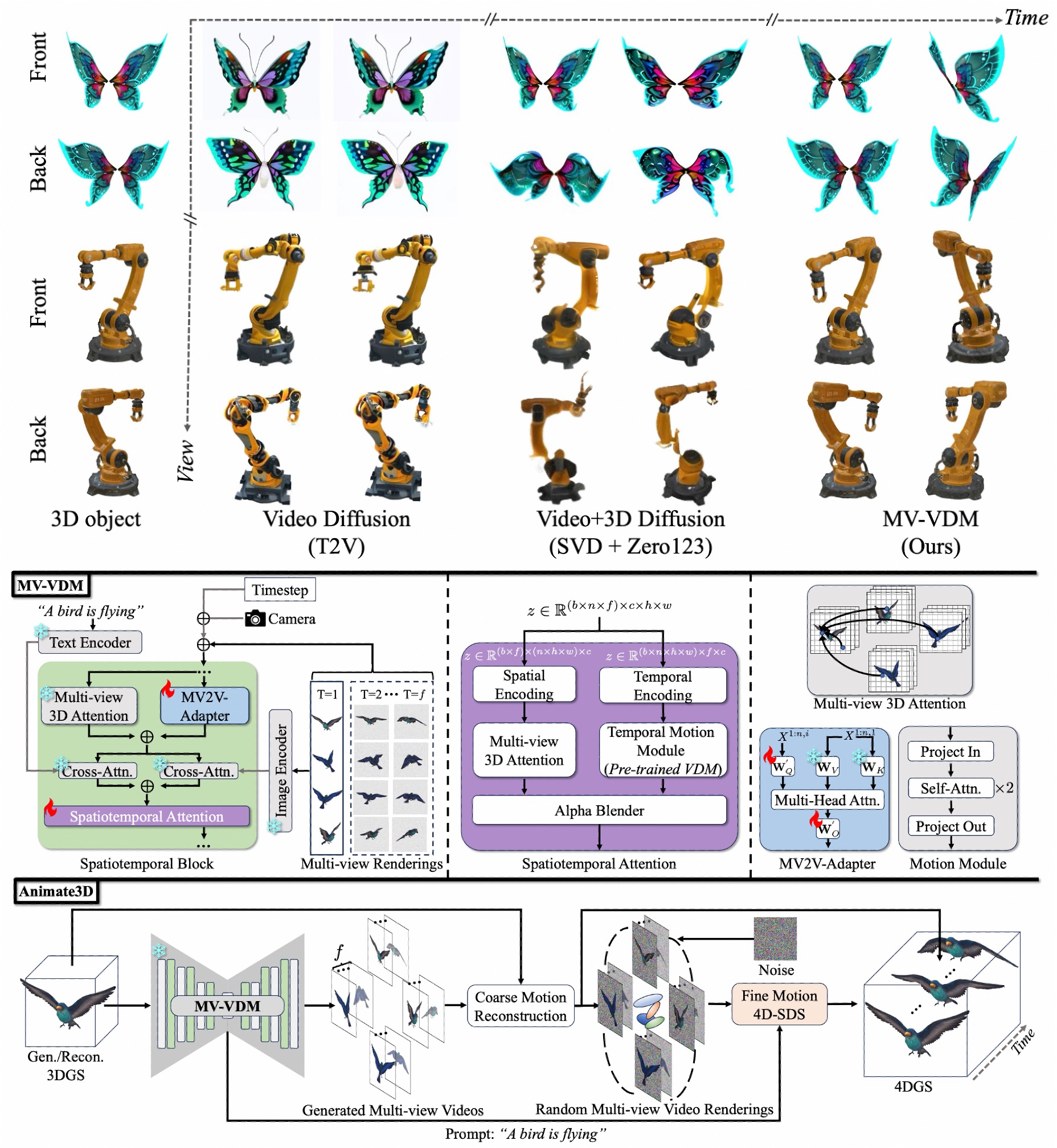
Yanqin Jiang, Chaohui Yu, Chenjie Cao, Fan Wang, Weiming Hu, Jin Gao NeurIPS 2024 page / paper / code In this work, we present Animate3D, a novel framework for animating any static 3D model. We present a large-scale multi-view video dataset (MV-Video) to train the novel multi-view video diffusion model (MV-VDM). |
|
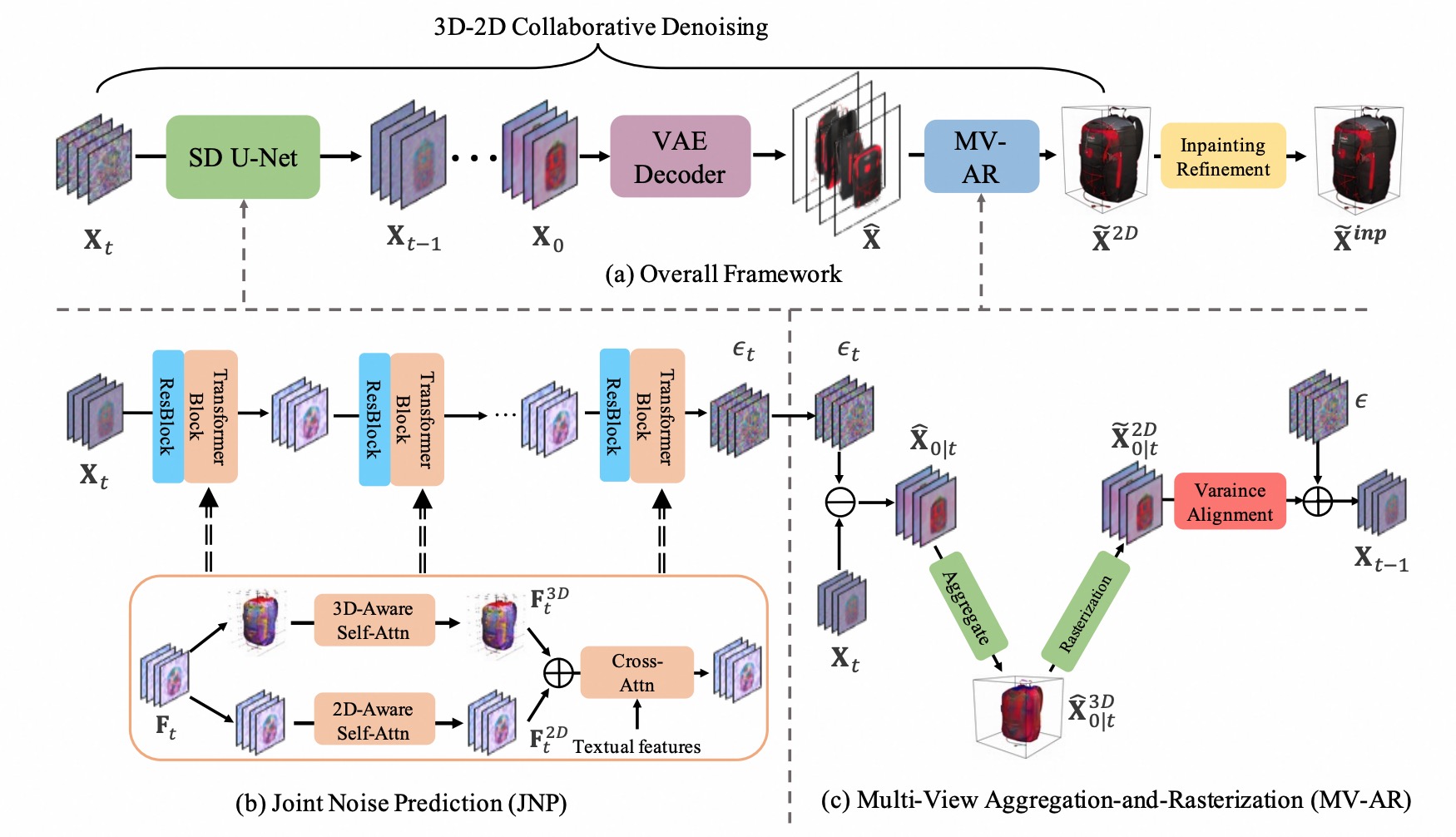
Shang Liu, Chaohui Yu, Chenjie Cao, Wen Qian, Fan Wang ECCV 2024 paper In this paper, we propose a Variance alignment based 3D-2D Collaborative Denoising framework, dubbed VCD-Texture, to address texture synthesis. |
|
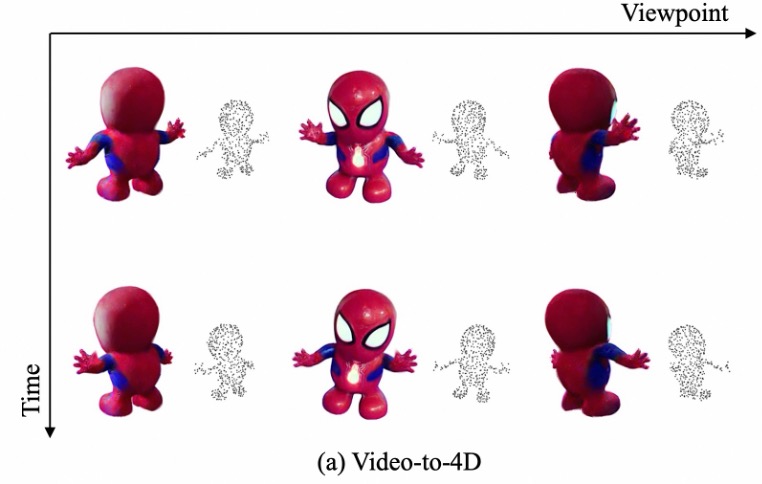
Zijie Wu, Chaohui Yu, Yanqin Jiang, Chenjie Cao, Fan Wang, Xiang Bai ECCV 2024 page / paper / code This paper proposes an efficient, sparse-controlled video-to-4D framework named SC4D, that decouples motion and appearance to achieve superior video-to-4D generation. |
|
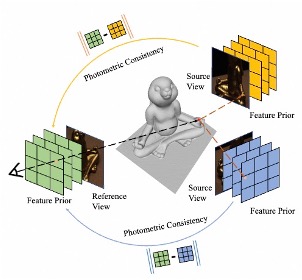
Xinlin Ren*, Chenjie Cao*, Yanwei Fu, Xiangyang Xue ECCV 2024 paper / code In this study, we comprehensively explore multi-view feature priors from seven pretext visual tasks, comprising thirteen methods. Our main goal is to strengthen Neural Surface Reconstruction (NSR) training by considering a wide range of possibilities. |

|
Chenjie Cao, Yunuo Cai, Qiaole Dong, Yikai Wang, Yanwei Fu CVPR 2024 page / paper / code We formulate the reference-guided multi-view synthesis as an contextual inpainting issue, which is addressed by pre-existing attention modules of pre-trained Text-to-Image model through prompt tuning. |

|
Yikai Wang, Chenjie Cao, Qiaole Dong, Yifan Li, Yanwei Fu TMLR 2024 page / paper / data We employ a single diffusion generative model to address various sub-tasks with task-specific prompts. |
|
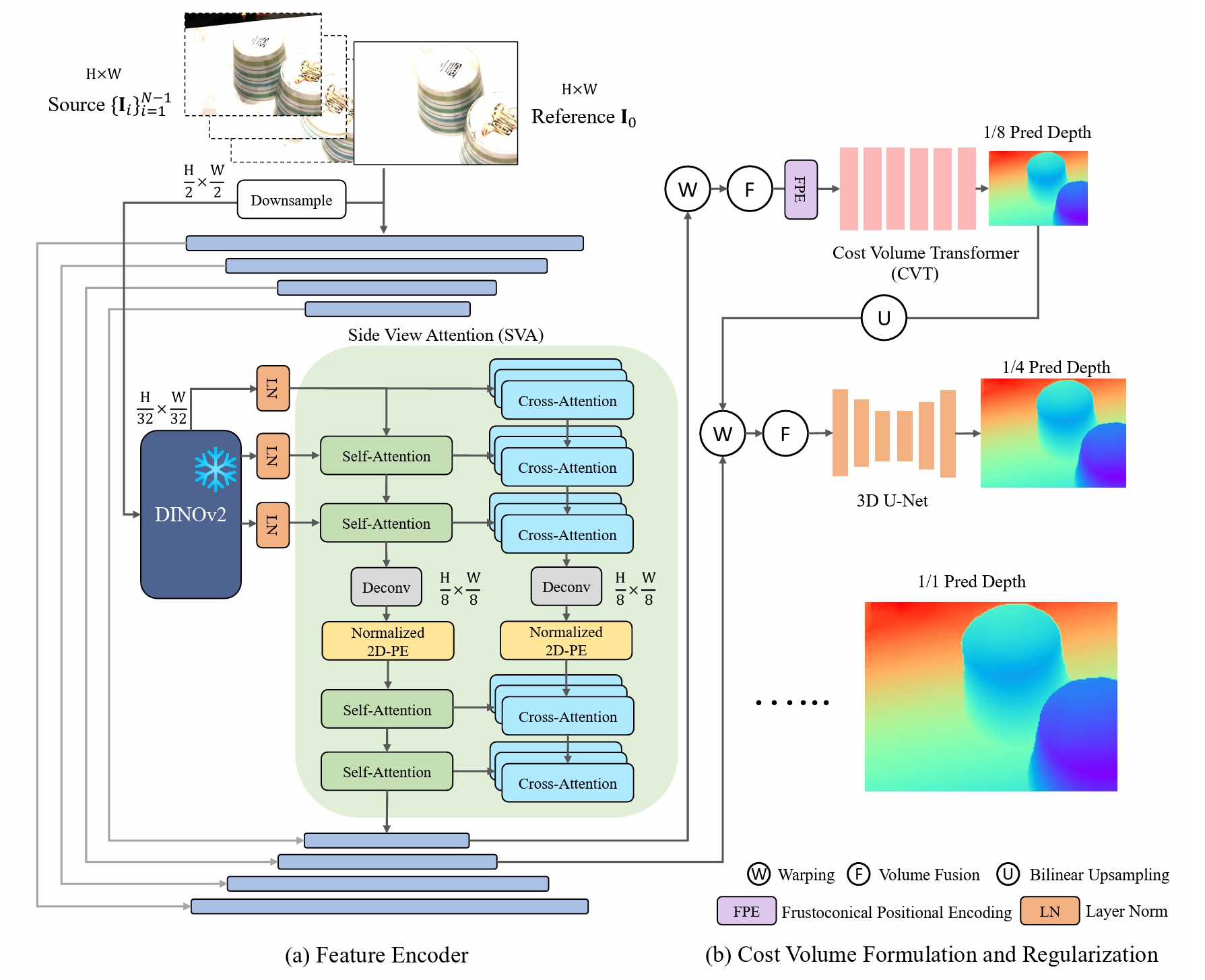
Chenjie Cao*, Xinlin Ren*, Yanwei Fu ICLR 2024 paper / code We introduce MVSFormer++, a method that prudently maximizes the inherent characteristics of attention to enhance various components of the MVS pipeline. |
|
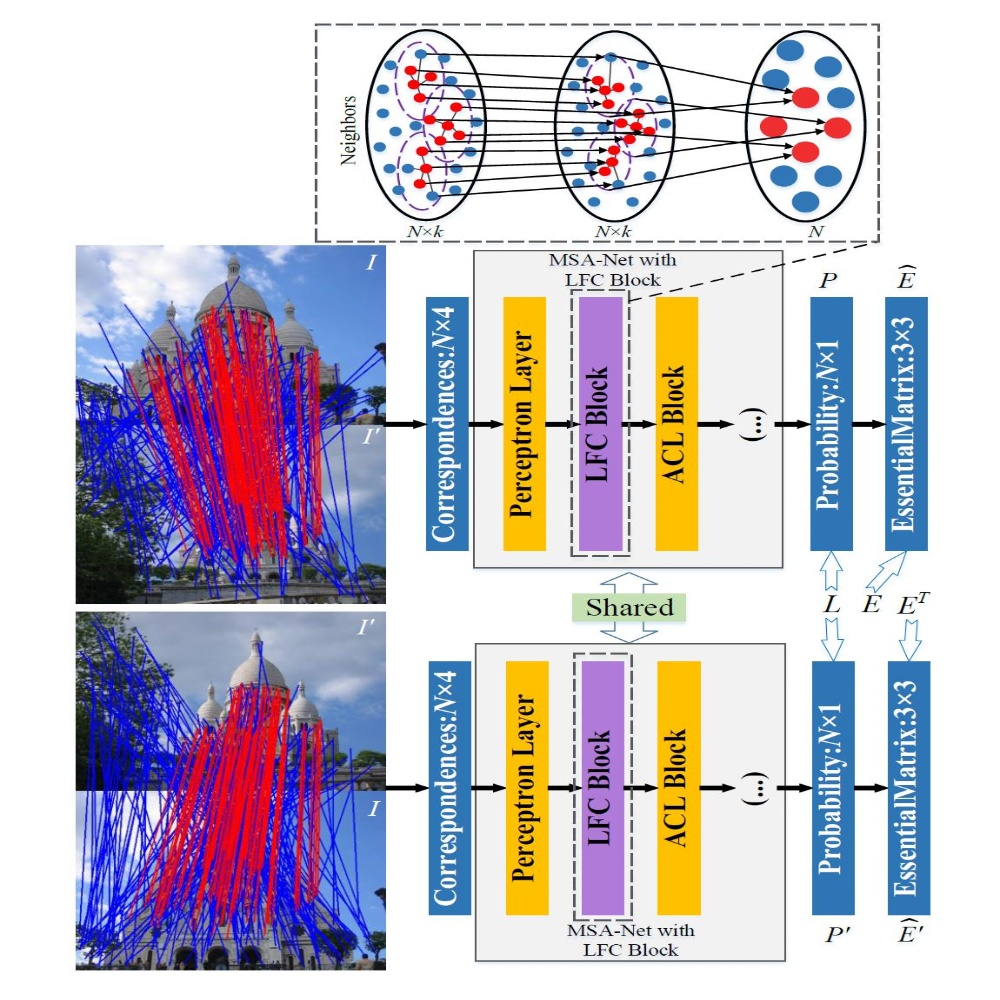
Linbo Wang, Jing Wu, Xianyong Fang, Zhengyi Liu, Chenjie Cao, Yanwei Fu ACMMM 2023 paper A Siamese network with a reciprocal loss is proposed to classify inliers/outliers for two-view matching. |

|
Chenjie Cao, Yanwei Fu ICCV 2023 page / paper / code Matching pairs located in spatially informative keypoints of both reference and target views enjoy better pose estimation. Thus a transformer-based cascaded matching model and a simple yet effective NMS filter are proposed. |

|
Chenjie Cao*, Qiaole Dong*, Yanwei Fu TPAMI 2023 page / paper / code The extension of CVPR work --ZITS. We further discuss the influence of various image priors on inpainting, and choice to use learning-based edges (L-Edge) as the new prior to enhance the meaningful structure recovery. |
|
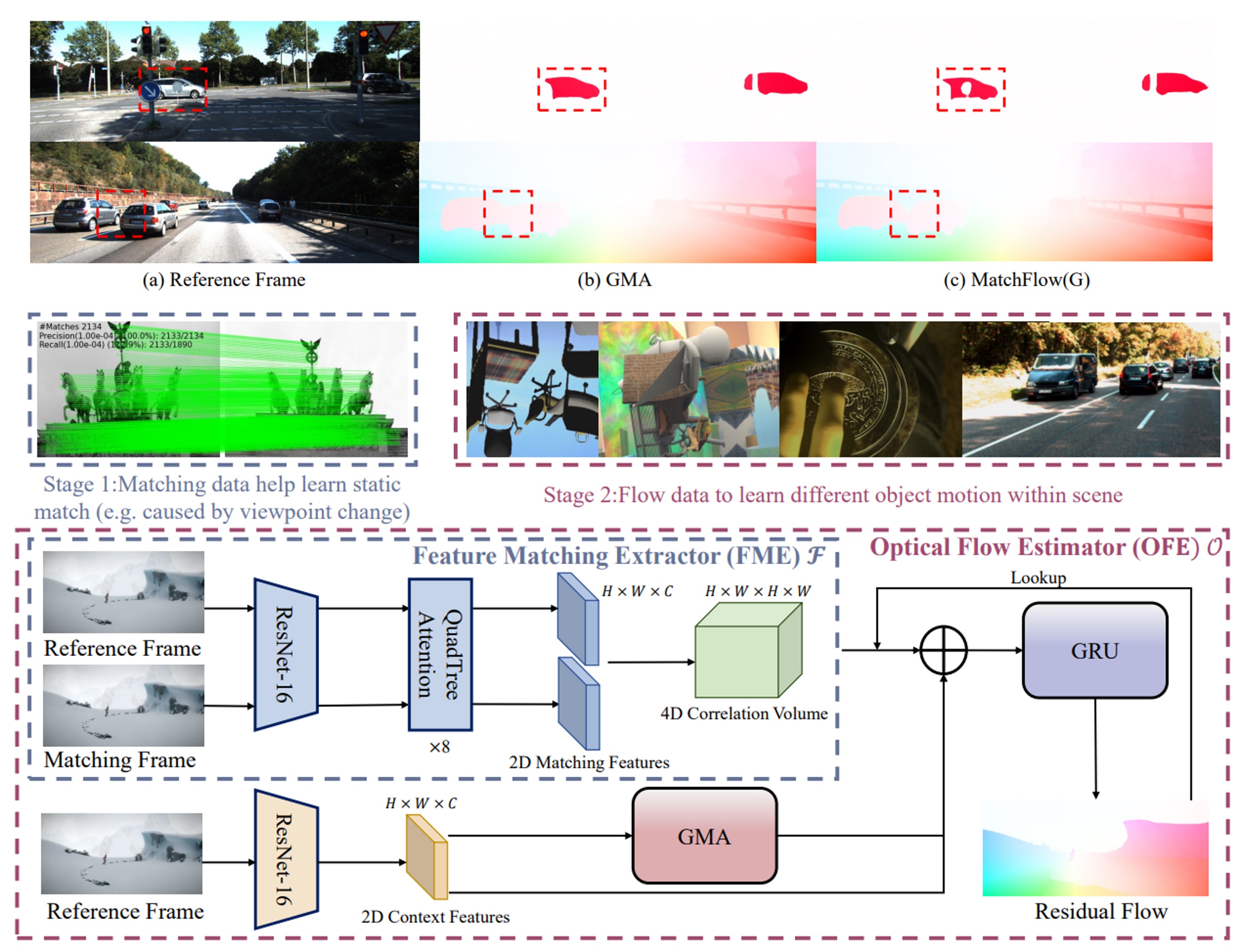
Qiaole Dong*, Chenjie Cao*, Yanwei Fu CVPR 2023 page / paper / code Improving the optical flow estimation through the image matching pre-text task. |
|
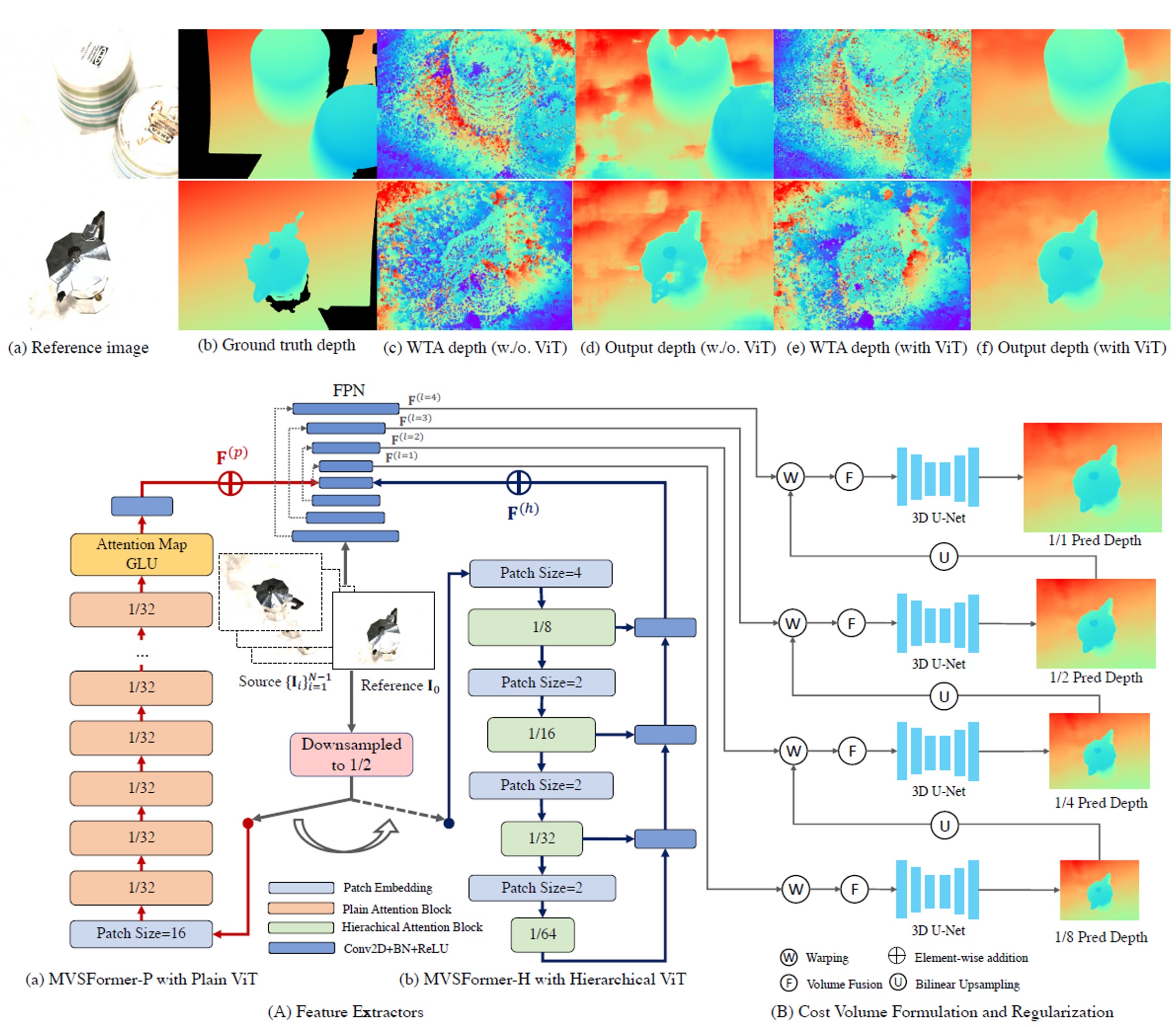
Chenjie Cao, Xinlin Ren, Yanwei Fu TMLR 2023 openreview / paper / code We explore the usage of pre-trained ViTs for multi-view stereo, and further propose to unify both classification and regression-based depth predictions. MVSFormer achieves 1-st place in Tanks-and-Temple, and achieve 2-nd place in GigaMVS2022. |
|
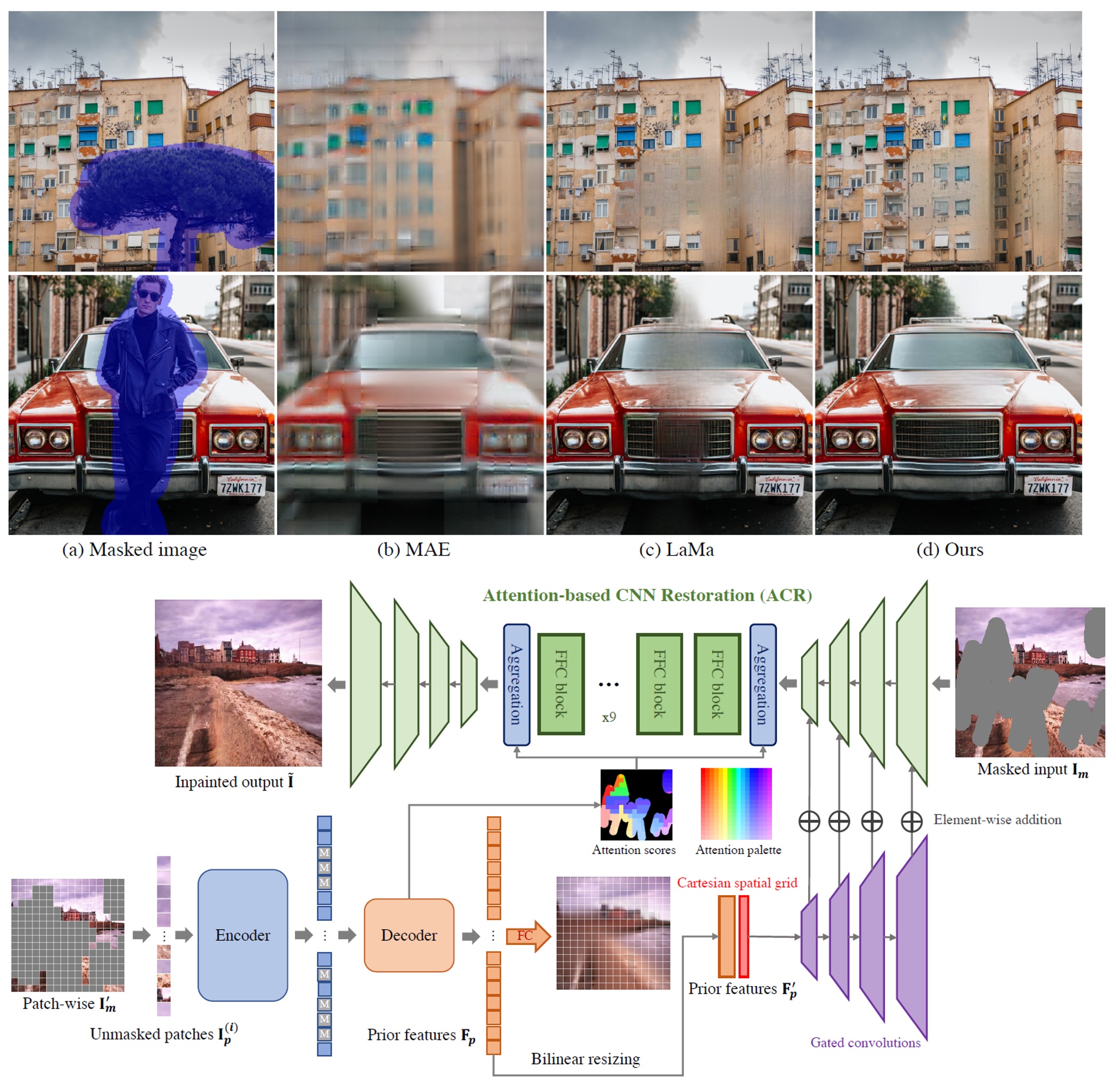
Chenjie Cao*, Qiaole Dong, Yanwei Fu ECCV 2022 page / paper / code Improving the image inpainting with Masked AutoEncoder pre-training and attention-based restoration. |

|
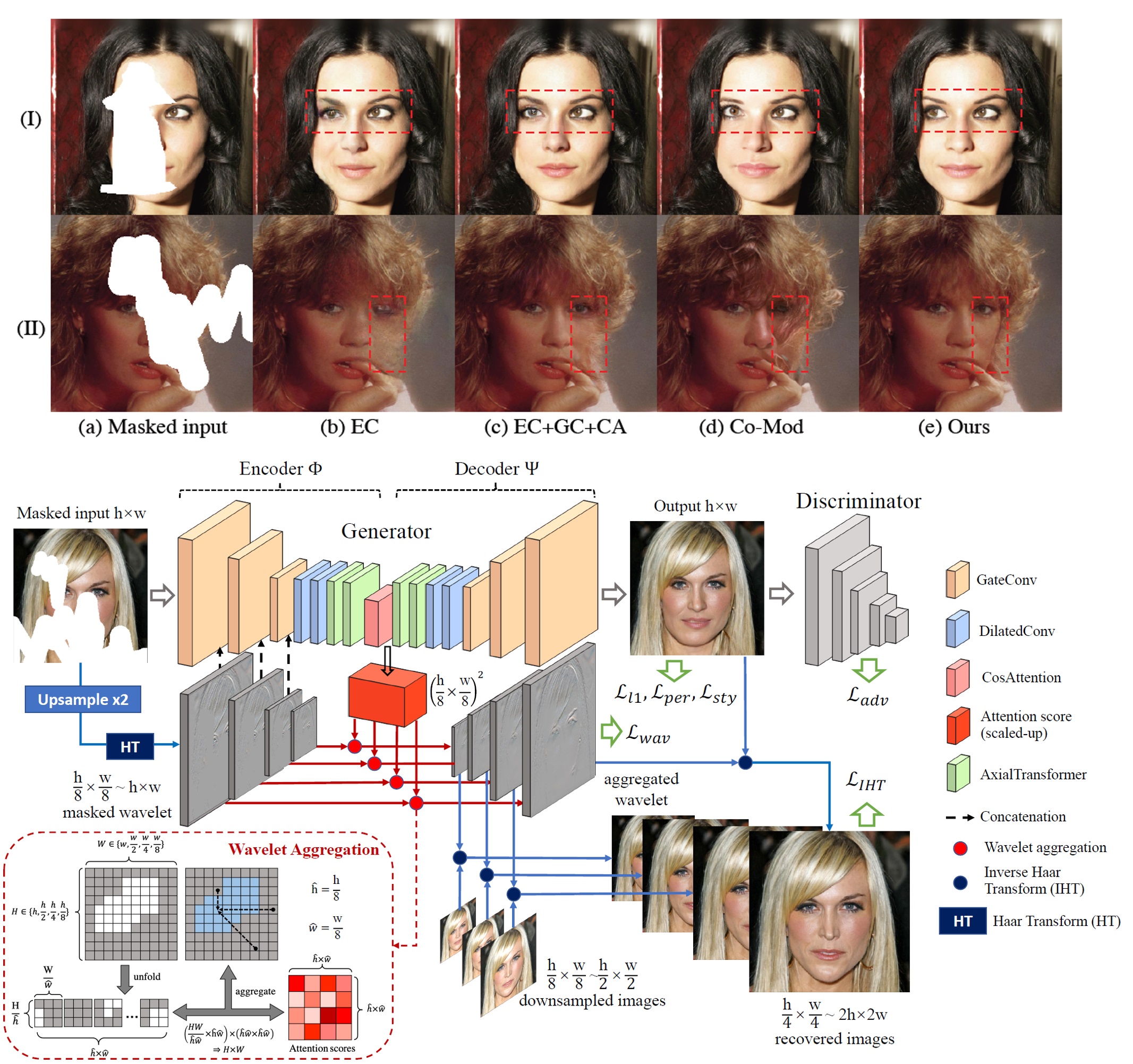
Qiaole Dong*, Chenjie Cao*, Yanwei Fu CVPR 2022 page / paper / code Learning structural priors (lines, edges) with transformers at first, then recovering textures with FFC based CNNs. |
|
Chenjie Cao, Chengrong Wang, Yuntao Zhang, Yanwei Fu Preprint paper Firstly introducing wavelet prior for image inpainting. We also use axial-transformer to enhance the face/structural recovery. |
|
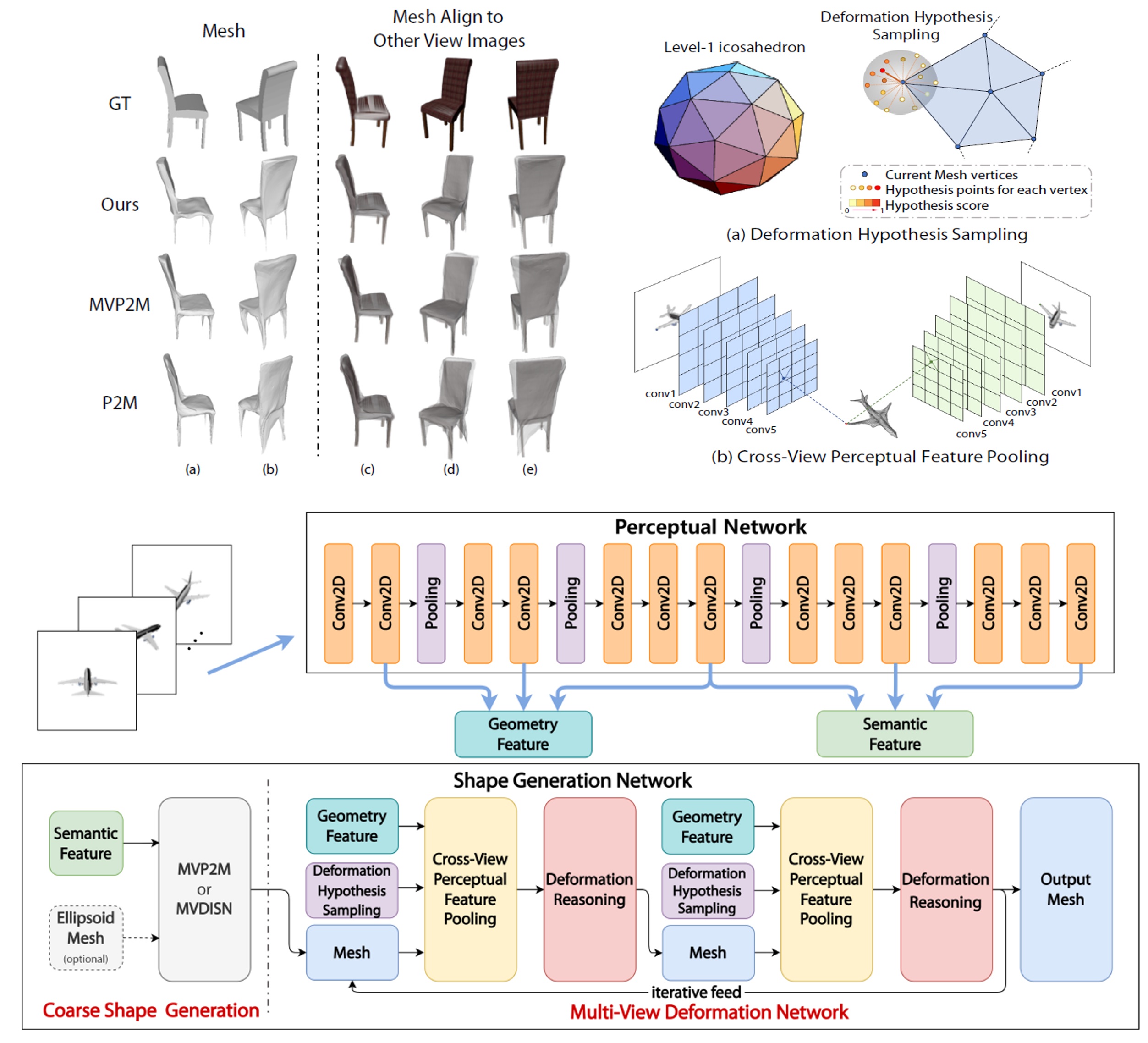
Chao Wen*, Yinda Zhang*, Chenjie Cao, Zhuwen Li, Xiangyang Xue, Yanwei Fu TPAMI 2022 page / paper / code The extension of P2M++, which makes P2M++ also work on SDF-based methods. |
|
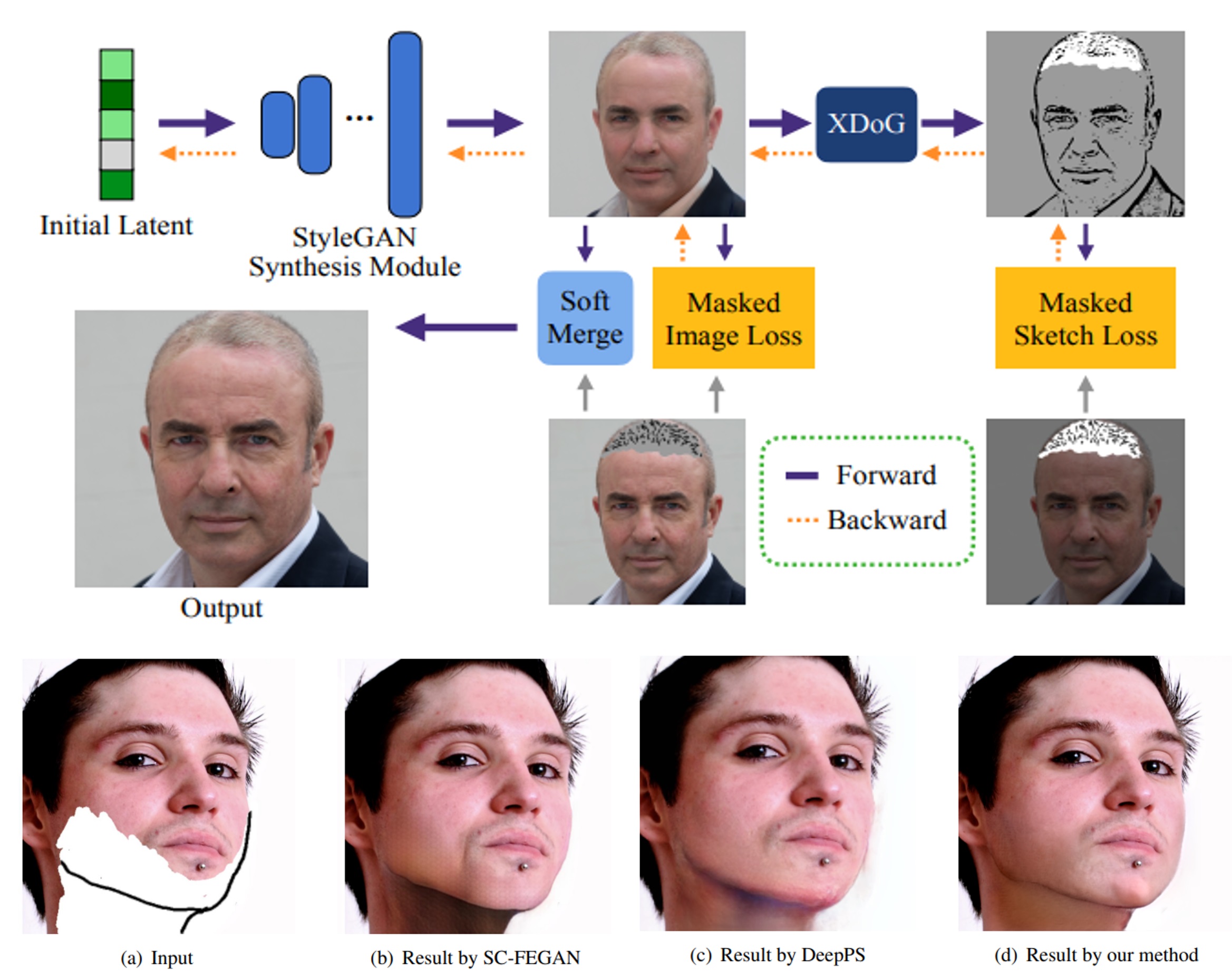
Chengrong Wang, Chenjie Cao, Yanwei Fu, Xiangyang Xue ICASSP 2022 paper Leveraging GAN inversion and differentiable edge detector to achieve an effective face editing. |
|
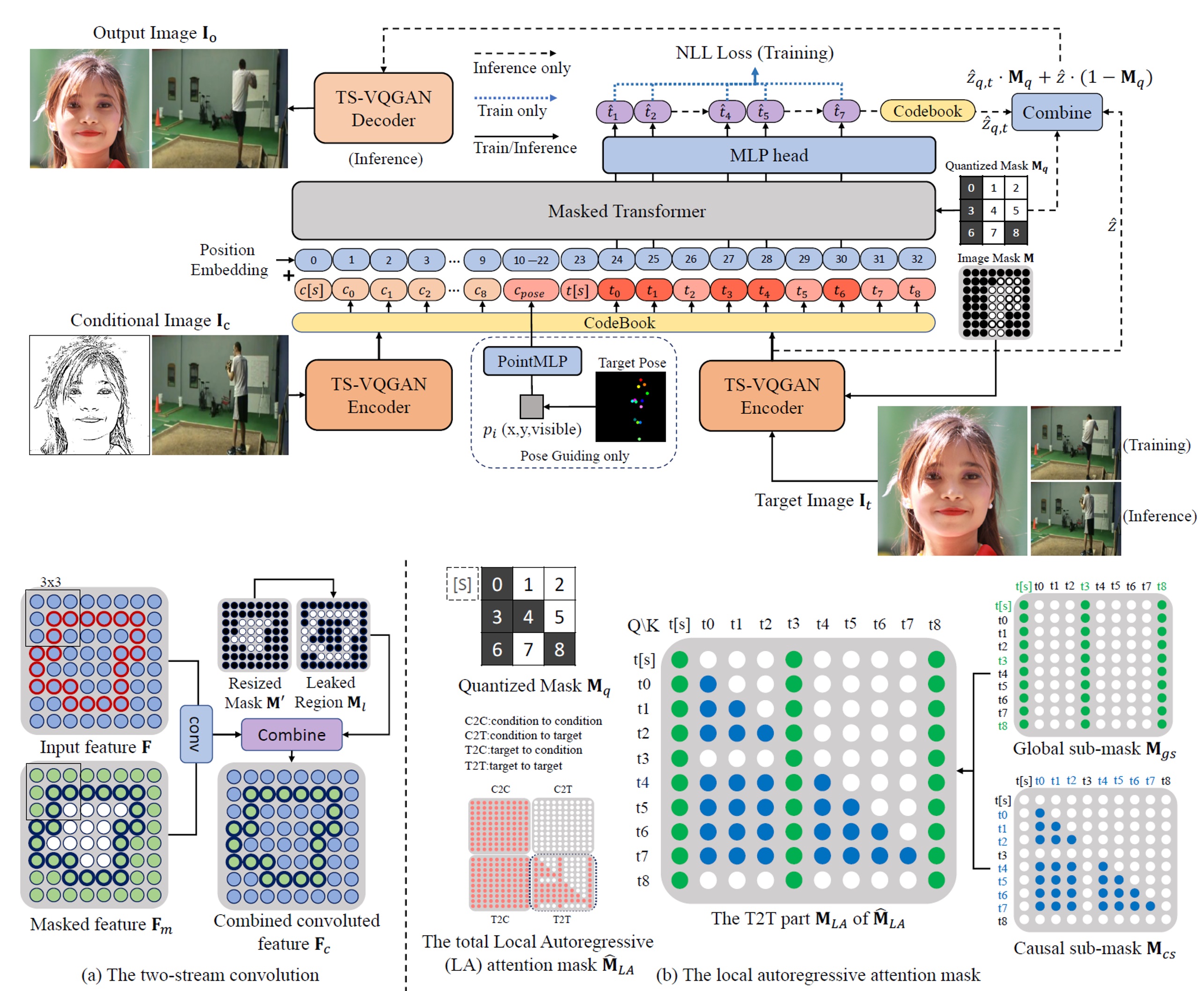
Chenjie Cao, Yuxin Hong, Xiang Li, Chengrong Wang, Chengming Xu, XiangYang Xue, Yanwei Fu NeurIPS 2021 paper / code Propose the local autoregressive for local editing. The two-stream convolution is proposed to tackle information leakage. |

|
Chenjie Cao, Yanwei Fu ICCV 2021 page / paper / code We firstly introduce segment lines to improve the image inpainting. |

|
Liang Xu, Xuanwei Zhang, Lu Li, Hai Hu, Chenjie Cao, Yudong Li, Yechen Xu, Kai Sun, Dian Yu, Cong Yu, Yin Tian, Qianqian Dong, Weitang Liu, Bo Shi, Yiming Cui, Junyi Li, Jun Zeng, Rongzhao Wang, Weijian Xie, Yanting Li, Yina Patterson, Zuoyu Tian, Yiwen Zhang, He Zhou, Shaoweihua Liu, Zhe Zhao, Qipeng Zhao, Cong Yue, Xinrui Zhang, Zhengliang Yang, Kyle Richardson, Zhenzhong Lan COLING 2020 page / paper / code A comprehensive Chinese NLP benchmark. |
|
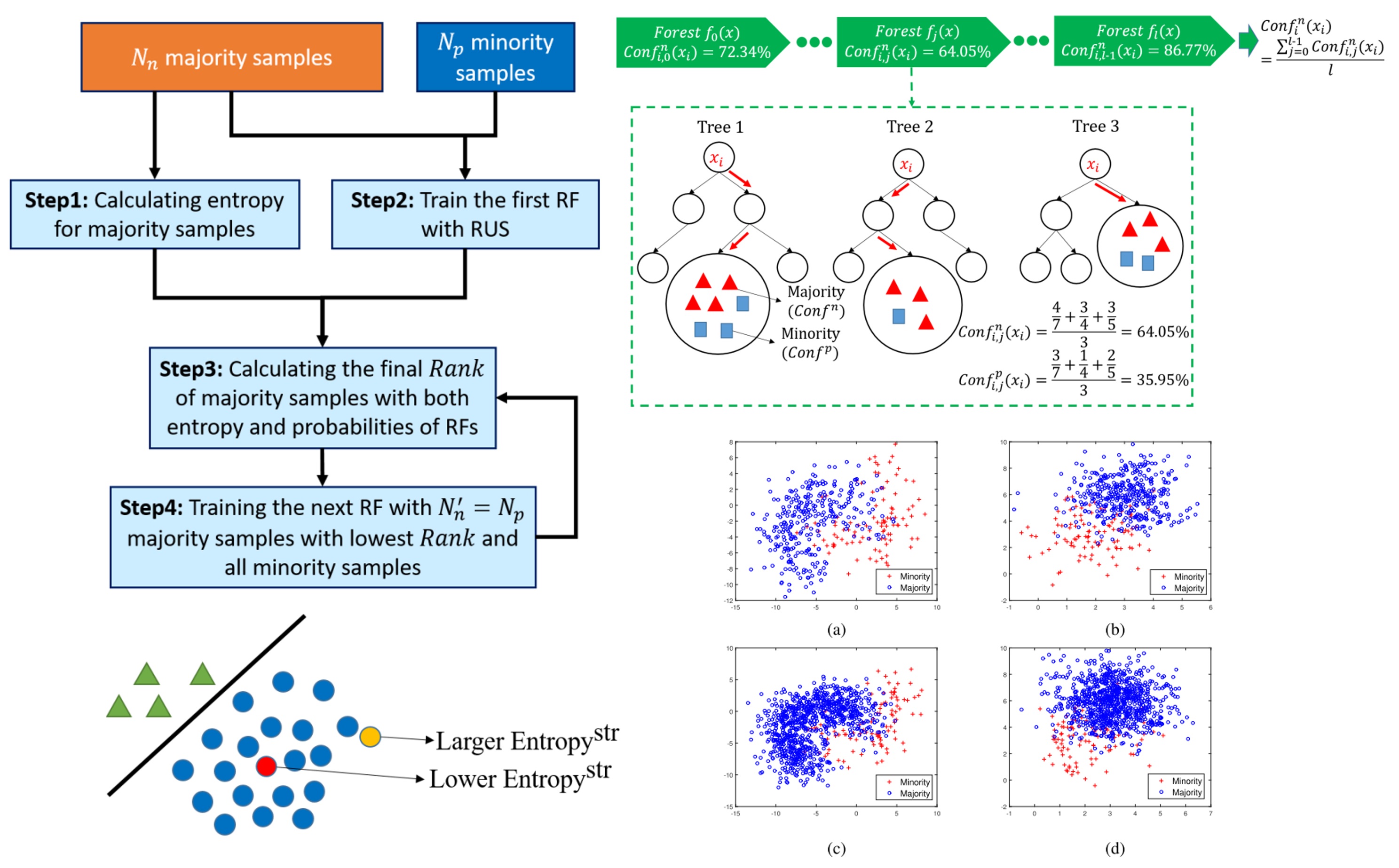
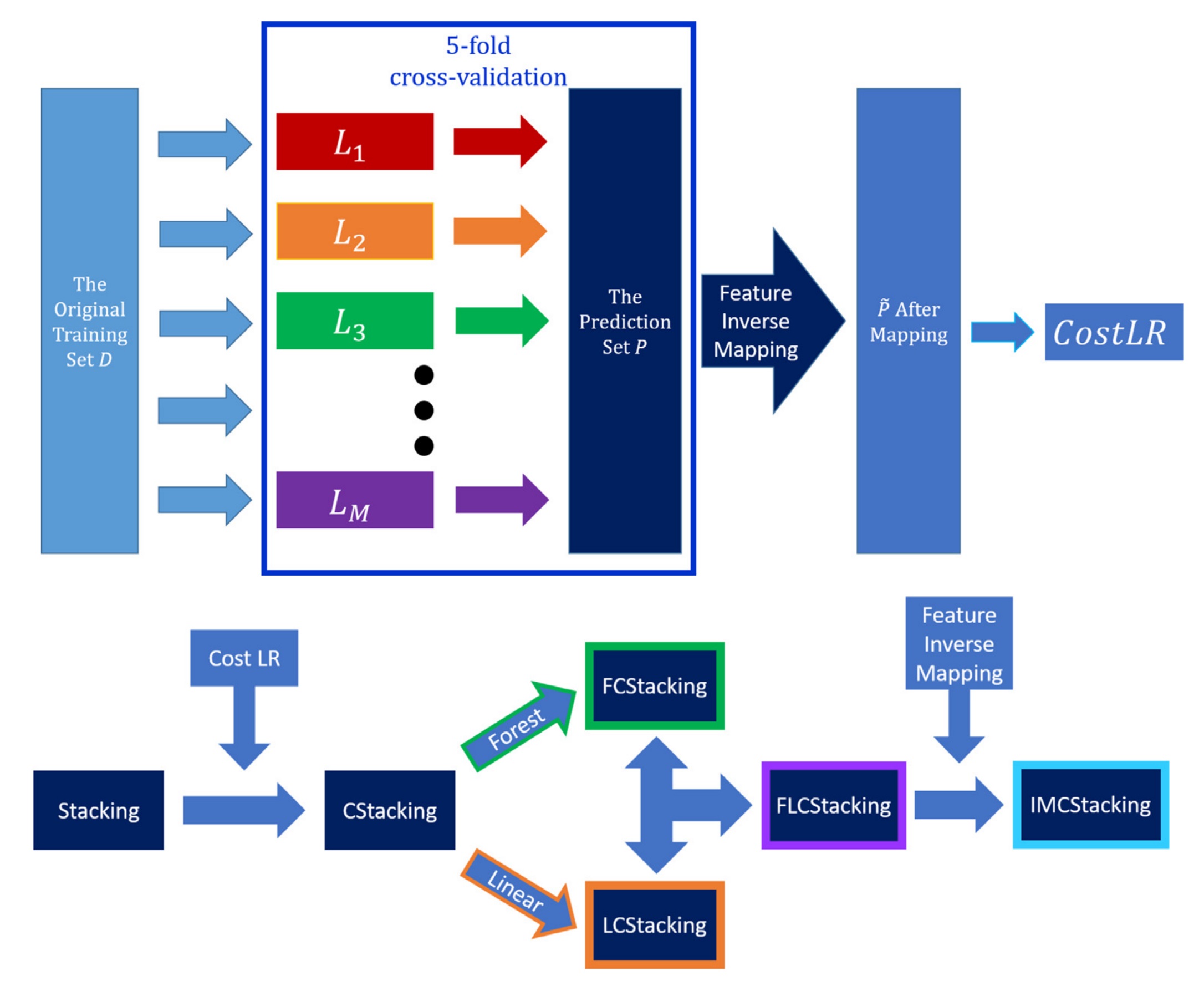
Zhe Wang, Chenjie Cao, Yujin Zhu TNNLS 2020 paper My early work about using ensemble learning to address imbalanced problems. |
|
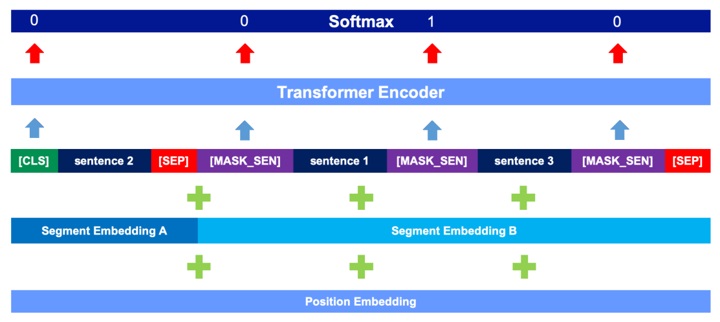
Jiahao Chen, Chenjie Cao, Xiuyan Jiang LREC 2020 paper Improving the BERT pre-training with Sentence Insertion. SiBert won 1-st of CMRC2019. |

|
Zhe Wang, Chenjie Cao Neural Network 2019 paper My early work about using ensemble learning to address imbalanced problems. |
|
Chenjie Cao, Zhe Wang KBS 2018 paper My early work about using ensemble learning to address imbalanced problems. |
|
Li DongDong, Zhe Wang, Chenjie Cao, Yu Liu ASC 2018 paper My early work about using SVDD to address imbalanced problems. |
|
|
| Second-Place in GigaReconstruction 2022. |
| Reviewer in TPAMI, IJCV, ACMMM2023, CVPR2023, NeurIPS 2022,2023, ICML2023, ICLR2023. |
| Yanwei Fu, Shenghua Gao, Chenjie Cao and Qiaole Dong. Tutorial: The Priors Guided Image Editing and Synthesis in ACCV2022. |
|
|